If participants know which group they are assigned to, there is a risk that they might change their behaviour in a way that would influence the results. If researchers know which group a participant is assigned to, they might act in a way that reveals the assignment or directly influences the results.
Double blinding guards against these risks, ensuring that any difference between the groups can be attributed to the treatment.
Published on
6 May 2022
by
Lauren Thomas.
Revised on
13 April 2023.
In a scientific study, a control group is used to establish a cause-and-effect relationship by isolating the effect of an independent variable.
Researchers change the independent variable in the treatment group and keep it constant in the control group. Then they compare the results of these groups.
Using a control group means that any change in the dependent variable can be attributed to the independent variable.
A cross-sectional study is a type of research design in which you collect data from many different individuals at a single point in time. In cross-sectional research, you observe variables without influencing them.
Researchers in economics, psychology, medicine, epidemiology, and the other social sciences all make use of cross-sectional studies in their work. For example, epidemiologists who are interested in the current prevalence of a disease in a certain subset of the population might use a cross-sectional design to gather and analyse the relevant data.
Published on
5 May 2022
by
Lauren Thomas.
Revised on
24 October 2022.
In a longitudinal study, researchers repeatedly examine the same individuals to detect any changes that might occur over a period of time.
Longitudinal studies are a type of correlational research in which researchers observe and collect data on a number of variables without trying to influence those variables.
While they are most commonly used in medicine, economics, and epidemiology, longitudinal studies can also be found in the other social or medical sciences.
Published on
4 May 2022
by
Lauren Thomas.
Revised on
12 April 2023.
In research that investigates a potential cause-and-effect relationship, a confounding variable is an unmeasured third variable that influences both the supposed cause and the supposed effect.
It’s important to consider potential confounding variables and account for them in your research design to ensure your results are valid.
Published on
3 May 2022
by
Lauren Thomas.
Revised on
18 December 2023.
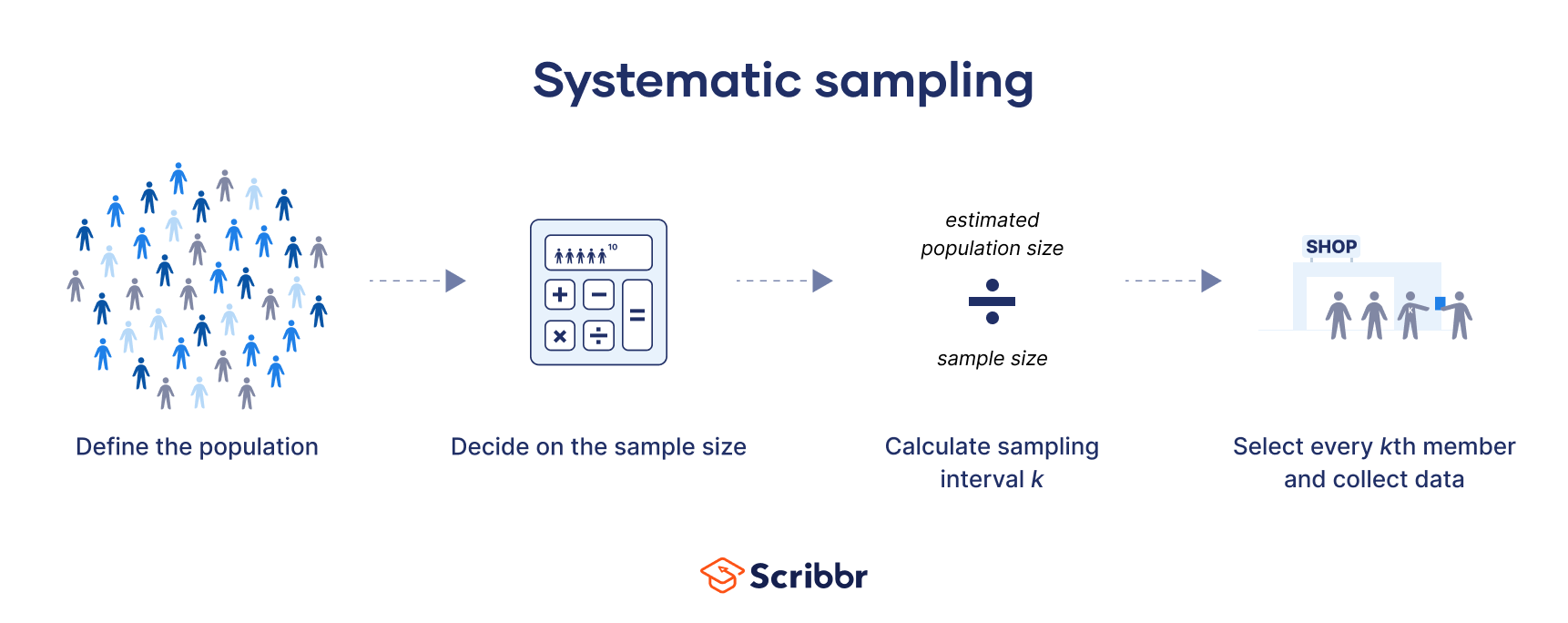
Systematic sampling is a probability sampling method in which researchers select members of the population at a regular interval (or k) determined in advance.
If the population order is random or random-like (e.g., alphabetical), then this method will give you a representative sample that can be used to draw conclusions about the population.
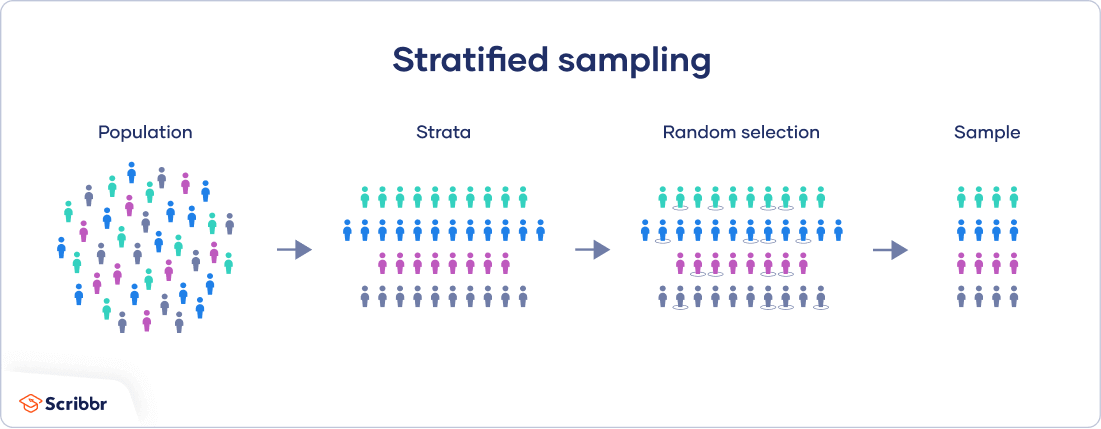
In a stratified sample, researchers divide a population into homogeneous subpopulations called strata (the plural of stratum) based on specific characteristics (e.g., race, gender identity, location). Every member of the population studied should be in exactly one stratum.
Each stratum is then sampled using another probability sampling method, such as cluster or simple random sampling, allowing researchers to estimate statistical measures for each subpopulation.
Researchers rely on stratified sampling when a population’s characteristics are diverse and they want to ensure that every characteristic is properly represented in the sample.
Published on
3 May 2022
by
Lauren Thomas.
Revised on
13 February 2023.
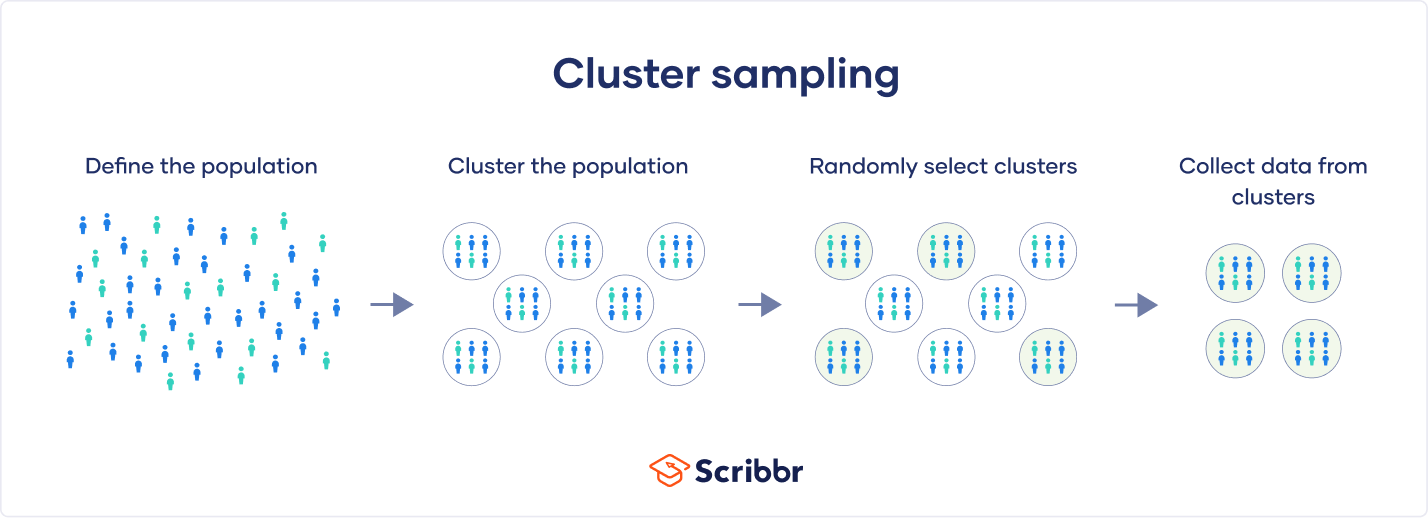
In cluster sampling, researchers divide a population into smaller groups known as clusters. They then randomly select among these clusters to form a sample.
Cluster sampling is a method of probability sampling that is often used to study large populations, particularly those that are widely geographically dispersed. Researchers usually use pre-existing units such as schools or cities as their clusters.
Published on
3 May 2022
by
Lauren Thomas.
Revised on
18 December 2023.
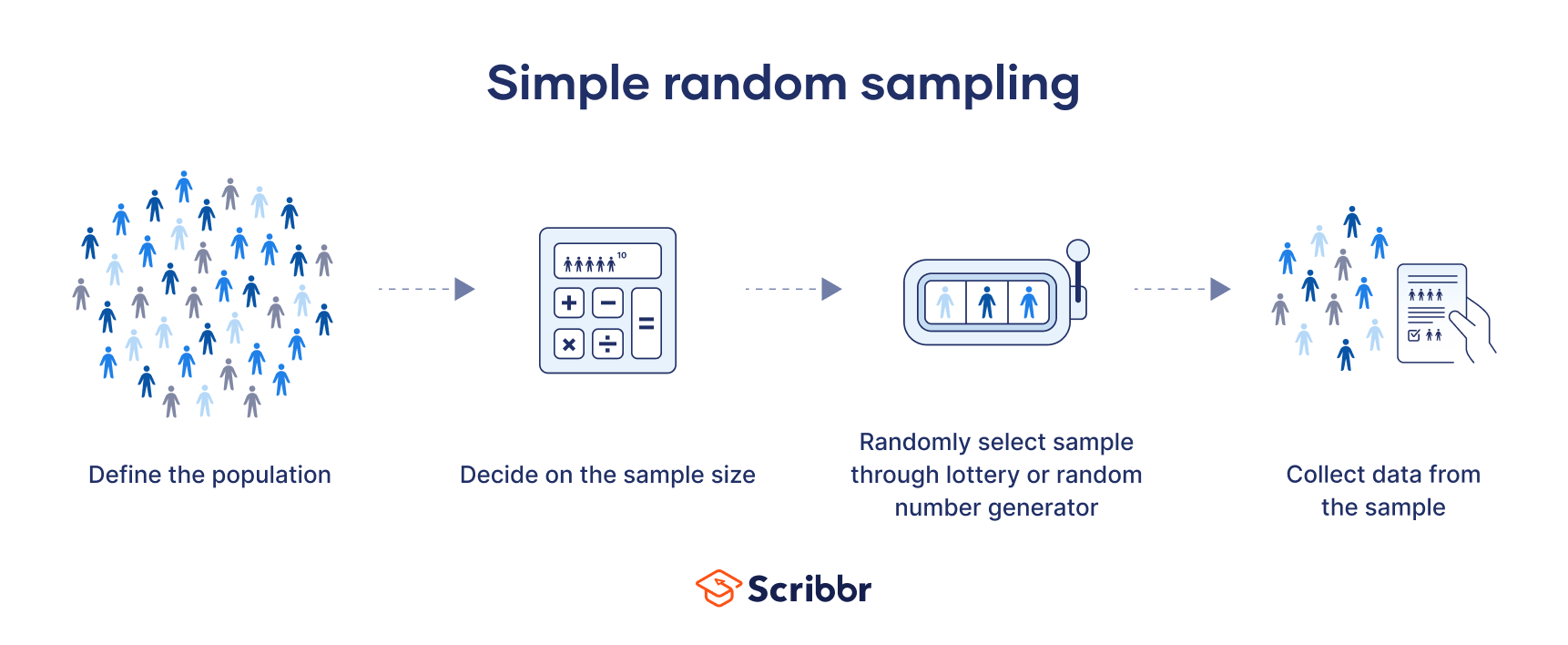
A simple random sample is a randomly selected subset of a population. In this sampling method, each member of the population has an exactly equal chance of being selected, minimising the risk of selection bias.
This method is the most straightforward of all the probability sampling methods, since it only involves a single random selection and requires little advance knowledge about the population. Because it uses randomisation, any research performed on this sample should have high internal and external validity.
Example: Random samplingThe American Community Survey (ACS) uses simple random sampling. Officials from the United States Census Bureau follow a random selection of individual inhabitants of the United States for a year, asking detailed questions about their lives in order to draw conclusions about the whole population of the US.
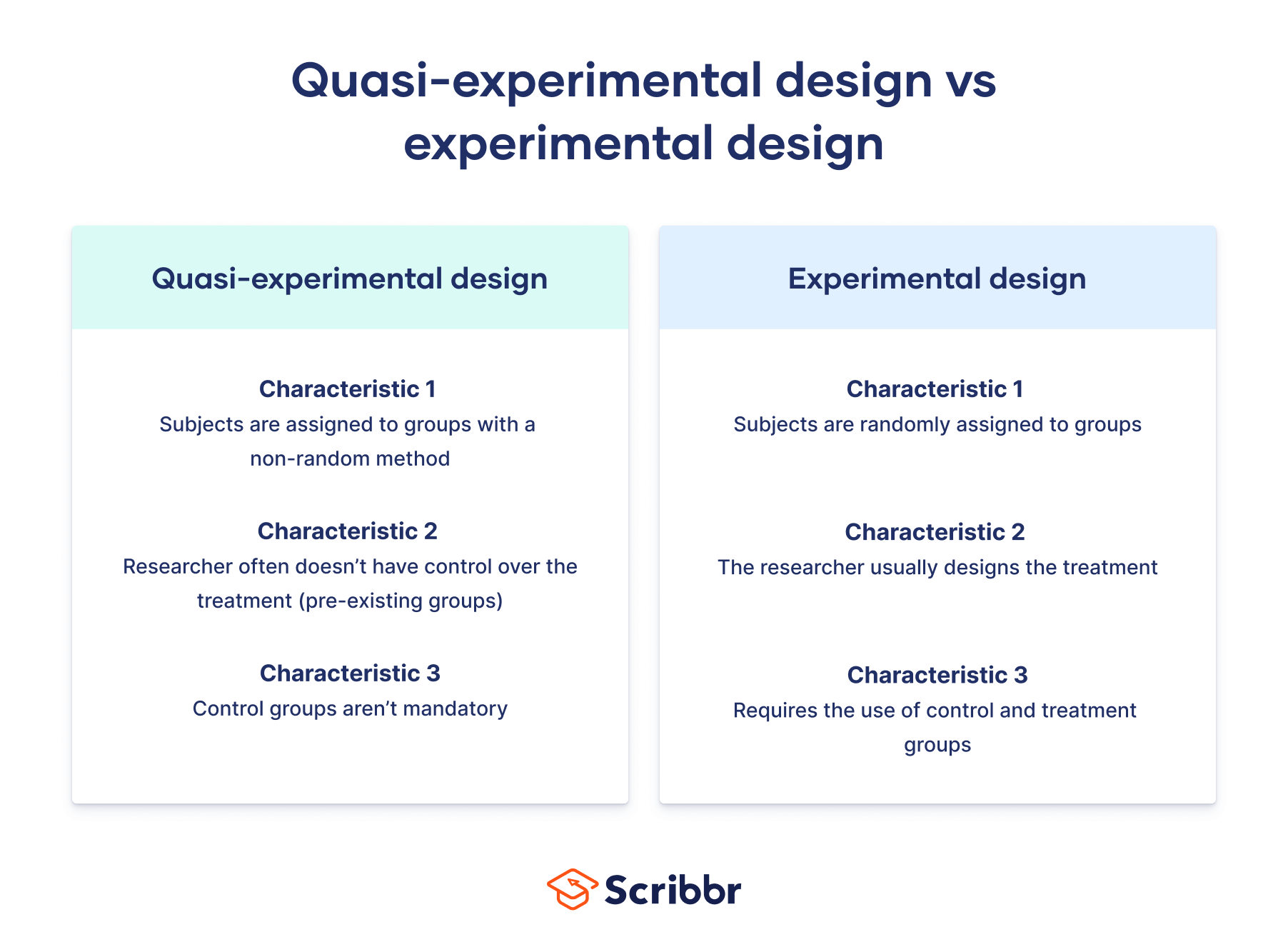
However, unlike a true experiment, a quasi-experiment does not rely on random assignment. Instead, subjects are assigned to groups based on non-random criteria.
Quasi-experimental design is a useful tool in situations where true experiments cannot be used for ethical or practical reasons.